|
|
|
Investigadores de University of Massachusetts Amherst han descubierto un nuevo algoritmo para resolver un problema de búsqueda en red que ha estado en el punto de mira de sociólogos y científicos de la computación durante años.
Estos científicos han creado un algoritmo (conjunto de reglas y operaciones para resolver un tipo de problema matemático) que ayuda a explicar los hallazgos sociológicos que llevó a crear la teoría de los seis grados de separación, que dice que cualquier persona está separada de cualquier otra por seis grados de separación.
Este algoritmo tendría aplicaciones importantes en redes de comunicación, mejora en la respuesta frente a la difusión de virus informáticos, etc.
El algoritmo fue presentado por Özgür S ims ek y David Jensen en el décimo noveno congreso internacional sobre inteligencia artificial en Edimburgo, y describe un modo eficiente para efectuar busquedas en unos casos particulares de red.
Según los investigadores es aplicable a un variado número de redes como redes peer-to-peer, www, redes Ad-doc wireless, etc. Y es especialmente bueno en el tipo de redes dinámicas y de configuración variable no centralizadas como el último caso mencionado.
La teoría de los seis grados de separación está basada en unos resultados obtenidos por Milgram y Travers en la década de los sesenta. Se solicitó a diversas personas que mandarán una carta hacia un destinatario determinado, pero a través de una cadena de conocidos. El resultado fue que sólo después de seis interacciones la carta llegaba a dicho destinatario.
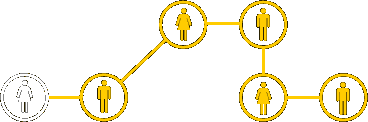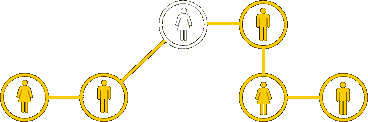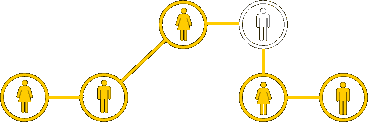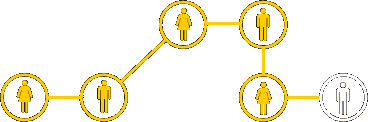
Normalmente este tipo de red tiene una configuración o incluso una topología general desconocida, pues esta última sólo se conoce localmente, ya que la red está descentralizada. Cada individuo de la cadena conoce sólo de donde viene la información y adonde va a mandarla, pero no es consciente de la red en su conjunto. Tareas como la búsqueda en sistemas de ficheros compartidos del tipo peer-to-peer (Kazaa, Emule, etc) o la navegación por la www están basados en la misma estructura.
Los voluntarios que participaron en el experimento de los sesenta mandaron cartas muy eficientemente porque probablemente combinaron características que ahora se usan en redes de comunicación. La gente tiende a asociarse con gente similares a ellos mismos, y también sabemos que haya algunas personas que son más gregarias que otras. Usando estas dos características la búsqueda del objetivo, incluso si se desconoce la estructura de la red en su totalidad, es más eficiente.
La primera característica de este tipo de redes descansa sobre la tendencia a la similaridad o homofilia, que significa que los atributos de un nodo (un individuo del estudio de Travers y Milgram) tienden a estar correlacionado con otros nodos. Así, un madrileño conoce a otros madrileños y lo mismo para cualquier otro tipo de característica como profesión, edad o aficiones.
La otra característica importante en este tipo de redes es que hay algunas personas que conocen a más personas que otras y esta característica les hace actuar como concentradores (“hubs”) de la red.
Si se toman ambas características en cuenta simultáneamente entonces podemos crear un algoritmo de búsqueda que toma un mensaje de un emisor y lo lleva al destinatario a través de la red de individuos gregarios. En el lenguaje de redes de telecomunicación esto favorece los nodos que maximizan la probabilidad de enlazar directamente con el blanco, y que es función tanto del grado como de la homofilia.
La combinación de estos dos aspectos dota al algoritmo de la capacidad de encontrar el blanco a través de un camino muy corto y de una manera muy eficiente, aun desconociendo la estructura de la red.
Para participar en un experimento más moderno sobre este problema pinche aquí [1].