Un algoritmo de inteligencia artificial aprende a jugar a Super Mario Broos o a Doom una vez dotado de sentido de la curiosidad.
|
Se ha puesto de moda, otra vez, el asunto de la inteligencia artificial (IA). Ahora incluso es un poco más inteligente de lo que fue en el pasado.
Google es una de las empresas que está apostando por este campo. Así por ejemplo, crearon AlphaGo un programa de aprendizaje profundo que juega al go y que el año pasado ganó a un maestro de este juego. Sobre miles de juegos simulados y reales, este algoritmo va aprendiendo cómo alcanzar estrategias que le permitan ganar. En NeoFronteras ya vimos en su día cómo funcionaba. Esta semana ha jugado contra Ke Jie, que es considerado el mejor jugador del mundo de Go, y el resultado ha sido que AlphaGo ha ganado por 3 a 0.
En este tipo de aproximaciones convencionales a la IA, el aprendizaje se da por un reforzamiento positivo. Hay algún tipo de recompensa por alcanzar una determinada meta, como pueda ser ganar una partida de go o conseguir la mayor puntuación posible en un juego. O también puede ser detener al mayor número posible de enemigos del videojuegos como Super Mario Bros o Doom. Esto permite relegar estrategias que no sirvan para conseguir muchos puntos o que detengan a pocos enemigos en un videojuego de este tipo.
Pero el mundo real no está lleno de recompensas que permitan este tipo de aprendizaje. En su lugar los humanos tienen una curiosidad innata que les ayuda a aprender mientras exploran el mundo. Además sienten placer cuando sacian esa curiosidad.
Básicamente ese tipo de programas como AlphaGo carecen de una curiosidad que les permita explorar otras opciones, para bien o para mal. Un algoritmo con sentido de la curiosidad podría aprender por sí mismo a descubrir y resolver problemas con los que nunca se hubiera enfrentado previamente.
Según Deepak Pathak (University of California, Berkeley) puede que la curiosidad humana sea la razón por la cual seamos tan buenos en una amplia gama de destrezas sin que necesariamente nos tengamos que sentar a aprenderlas porque previamente hemos hecho otras.
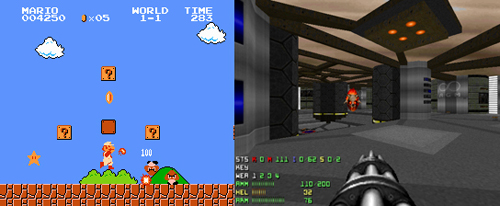
Este investigador ha desarrollado una IA motivada por la curiosidad capaz de jugar bien al nivel 1 de Super Mario Bros. Hay otro tipo de programas jugando mejor a este tipo de juegos y basados en otras estrategias, pero lo interesante es cómo esta IA logra este objetivo. Aunque este algoritmo no pase de la primera fase del juego, es sorprendente que haya aprendido a explorar, evitar trampas y matar enemigos armado solamente con el “deseo” de descubrir más acerca del mundo en el que se desarrolla ese juego. De este modo, se puede “plantear” qué es lo que pasa si “aprieta” un botón virtual de ese juego, apretarlo por curiosidad y ver qué sucede.
La idea del proyecto era saber si un programa de IA podría aprender a realizar un conjunto de tareas a partir de un autorreforzamiento del aprendizaje que provendría precisamente del sentido de curiosidad.
El programa experimentaría una recompensa (¿placer por aprender?) cuando con sus acciones aumentase la comprensión del ambiente en el que se desarrolla el juego y, en particular, las partes que lo afectan directamente. Así que, en lugar de buscar directamente la recompensa en el mundo del juego, el algoritmo es recompensado por explorar y por mejorar las destrezas que le permiten seguir haciendo descubrimientos acerca de ese mundo.
La IA de Pathak también aprendió a detener a los enemigos y a saltar sobre las trampas en el juego de Doom mientras aprendía a explorar la complicada estructura de habitaciones y pasadizos de este otro juego. Una pasada esa experiencia y con este nuevo bagaje, esta IA fue capaz entonces de superar el nivel 1 de Super Mario Bros, pese a que antes no había sido capaz.
Pero este algoritmo, de momento, tiene sus limitaciones. En promedio sólo explorar el 30% del nivel 1 una vez que no es capaz de encontrar el camino por una serie de pozos que sólo se pueden evitar a través de una secuencia en la que se presionan más de 15 botones virtuales. Así que, en lugar de lanzarse a una muerte segura, esta IA aprendió a volver sobre sus pasos y a parar al llegar a ese punto. El problema es que la IA no tenía ni idea de que había más por explorar en ese nivel más allá de los pozos.
Tampoco consiguió aprender de forma consistente a tomar atajos útiles en el juego cuando le mostraron menos del nivel y entonces sus ganas de exploración no eran los suficientemente saciadas.
Este investigador pretende usar este tipo de algoritmo para que un brazo robótico aprenda por curiosidad a manipular objetos o que el robot aspiradora Roomba explore mejor una casa y pueda limpiar todos los rincones en lugar de moverse al azar. El tiempo dirá si esta idea está ya lo suficiente madura.
Según Max Jaderberg (compañía Google) este tipo de aproximación a la IA permite acelerar el tiempo de aprendizaje y mejorar la eficiencia. Google ya usa este tipo de algoritmos de IA para explorar laberintos. Su “agente” aprende mucho más rápido que los algoritmos convencionales de reforzamiento de aprendizaje por aproximación. Además, requiere de menos experiencia y es más eficiente con los datos.
Copyleft: atribuir con enlace a http://neofronteras.com/?p=5557 [1]
Fuentes y referencias:
Artículo original. [2]
Fotos: Wikimedia Commons.