Posible límite a las IA
La ‘fiebre del oro’ de la IA por los datos de entrenamiento de chatbots podría quedarse pronto sin textos escritos por humanos
|
|
|
En cada época se ha denominado Inteligencia Artificial (IA) a distintos conceptos tecnológicos. Ahora, las nuevas IA que nos están invadiendo se basan en redes neuronales de aprendizaje profundo y en modelos de lenguaje.
Los peligros asociados a las IA ya los estamos viendo. Israel está usando una de estas IA a la hora de elegir blancos a bombardear, con el resultado de muchos inocentes muertos. No nos debemos de extrañar de ello, porque cuando se desarrolló la química, el primer uso masivo que se hizo fue la síntesis de todo tipo de gases tóxicos que se usaron en la primera guerra mundial. También vimos como física moderna desembocó en las explosiones de bombas nucleares sobre Japón al final de la segunda guerra mundial. Parece que tenemos cierta tendencia a usar cualquier tecnología novedosa para matarnos unos a otros más eficientemente. Las IA también pueden también desembocar en sistemas de vigilancia masiva que dejen a cualquier distopía orwelliana como un paraíso.
Un aspecto muy negativo y objetivo de esta tecnología es la gran cantidad de energía, con sus emisiones asociadas, que requieren tanto el entrenamiento como el funcionamiento en la nube de estos servicios. Pronto todos los asuntos de Internet, incluyendo esta misma web en la que lee esto, consumirá una proporción sustancial de toda la energía que produzca el ser humano y superará a los vuelos comerciales o a varios países desarrollado combinados. Al fin y al cabo, su crecimiento es exponencial. Encima este gasto de energía lleva aparejado un gasto descomunal de agua potable.
No queremos ver los límites que impone la Naturaleza y los microchips ya han alcanzado unos pocos nanometros de miniaturización, que a 10 átomos por nanometro, ya no deja mucho margen de mejora. Tampoco parece que los nuevos chips neuronales que se están fabricando mejoren sustancialmente el rendimiento y superen la actual eficacia.
El problema es que la nueva tecnofilia se ha consagrado ya como una nueva religión en donde no cabe la disidencia y todos dejarán que estos sistemas se infiltren en nuestros teléfonos móviles y en nuestras vidas. Además, la promesa, para unos pocos, de un becerro de oro aún más suculento hará que esta invasión sea inevitable. La legislación parece que tampoco quiere parar el mal uso de las IA.
Pero esta tecnología puede que ni siquiera sucumba a los límites ecológicos o climáticos, sino a su propia naturaleza. Al fin y al cabo, son tecnologías que se basan en la fuerza bruta.
Los modelos de lenguajes del estilo de Chat-GPT son entrenados con ingentes cantidades de textos, que, hasta ahora, estaban escritos por humanos. Para que estos sistemas mejoren se necesitan aún más datos de entrenamiento, pero hay un problema: no hay más datos. Estos sistemas de inteligencia artificial pronto podrían quedarse sin las decenas de billones de palabras que la gente ha escrito y compartido en línea.
Un nuevo estudio publicado el jueves por el grupo de investigación Epoch AI predice que las empresas de tecnología agotarán el suministro de datos de entrenamiento disponibles públicamente para modelos de lenguaje de IA aproximadamente hacia el cambio de década, en algún momento entre 2026 y 2032.
Comparándolo con una «fiebre del oro» que agota los recursos naturales finitos, Tamay Besiroglu sostiene que este campo podría enfrentarse a grandes desafíos para poder mantener su actual ritmo de crecimiento una vez que agote las reservas de escritura generada por humanos.
En el corto plazo, empresas como OpenAI, dueña de ChatGPT, y Google están compitiendo para asegurarse y, a veces, pagar, fuentes de datos de alta calidad para entrenar sus grandes modelos de lenguaje de IA. Así, por ejemplo, han firmando acuerdos para aprovechar el flujo constante de textos contenidos en foros como los de Reddit y de otros medios de comunicación, incluyendo periódicos.
A largo plazo, no habrá suficientes blogs nuevos, artículos de noticias y comentarios en las redes sociales para sostener la trayectoria actual de desarrollo de la IA, lo que presionará a las empresas para que aprovechen datos confidenciales que ahora se consideran privados (como correos electrónicos o mensajes de texto) y confiando en «datos sintéticos» menos fiables que hayan sido escupidos por los propios chatbots.
De hecho, Internet ya se está llenando con textos creados por estas IA que son bastante deficientes. Todos sabemos lo que ocurre cuando se pretende sacar calidad a partir de basura y esto no va a ser menos. Otros estudios señalan que si se entrenan a IA con resultados de IA los resultados son grotescos. Veremos este detalle más adelante.
«Aquí hay un serio cuello de botella. Si comienzas a superar esas limitaciones sobre la cantidad de datos que tienes, entonces ya no podrás ampliar tus modelos de manera eficiente. Y ampliar los modelos ha sido probablemente la forma más importante de ampliar sus capacidades y mejorar la calidad de su producción», dice Besiroglu.
Los investigadores hicieron sus proyecciones por primera vez hace dos años, poco antes del debut de ChatGPT, en un documento de trabajo que pronosticaba un límite más inminente para 2026 de datos de texto de alta calidad. Mucho ha cambiado desde entonces, incluidas nuevas técnicas que permitieron a los investigadores de IA hacer un mejor uso de los datos que ya tienen y, a veces, «sobreentrenarse» en las mismas fuentes varias veces.
Pero hay límites y, después de más investigaciones, Epoch prevé ahora que se queden sin datos de textos públicos en algún momento de los próximos dos a ocho años.
Besiroglu dice que los investigadores de IA se dieron cuenta hace más de una década de que expandir agresivamente dos ingredientes clave, en concreto la potencia informática y grandes reservas de datos de Internet, podría mejorar significativamente el rendimiento de los sistemas de IA.
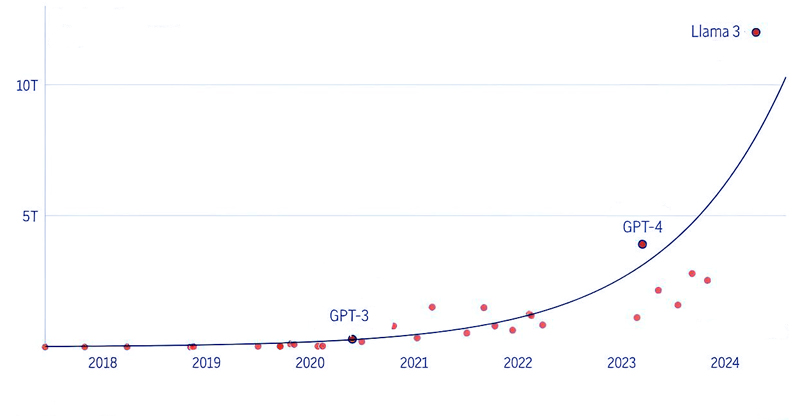
Según el estudio Epoch, la cantidad de datos de texto introducidos en los modelos de lenguaje de IA ha aumentado aproximadamente 2,5 veces por año. La empresa matriz de Facebook, Meta Platforms, afirmó recientemente que la versión más grande de su próximo modelo Llama 3, que aún no se ha lanzado, ha sido entrenada en hasta 15 billones de tokens, cada uno de los cuales puede representar una parte de una palabra.
Pero es discutible hasta qué punto vale la pena preocuparse por el cuello de botella de datos. «Creo que es importante tener en cuenta que no necesariamente necesitamos entrenar modelos cada vez más grandes», dice Nicolas Papernot, que no participó en el estudio de Epoch, pero que es profesor asistente de ingeniería informática en la Universidad de Toronto e investigador del Vector Institute for Artificial Intelligence, una organización sin fines de lucro.
Papernot sostiene que la construcción de sistemas de IA más capacitados también puede provenir de modelos de entrenamiento que estén más especializados para tareas específicas. Pero le preocupa entrenar sistemas de IA generativa con los mismos resultados que están produciendo, lo que lleva a una degradación del rendimiento conocida como «colapso del modelo».
El entrenamiento con datos generados por IA es como lo que sucede cuando fotocopias una imagen en una hoja de papel y luego fotocopias la fotocopia. Al final se pierde parte de la información y se degrada la imagen. No sólo eso, sino que la investigación de Papernot también ha descubierto que puede codificar aún más los errores, prejuicios e injusticias que ya están integrados en el ecosistema de la información.
Si las oraciones reales elaboradas por humanos siguen siendo una fuente fundamental de datos de la IA, quienes administran los tesoros más buscados (sitios web como Reddit y Wikipedia, así como editores de noticias y libros) se han visto obligados a pensar detenidamente sobre cómo se utilizan.
«Es un problema interesante en este momento que estemos teniendo conversaciones sobre recursos naturales sobre datos creados por humanos. No debería reírme de ello, pero lo encuentro algo sorprendente», dice Selena Deckelmann, directora de productos y tecnología de la Fundación Wikimedia, que administra Wikipedia.
Si bien algunos han tratado de excluir sus datos del entrenamiento de IA, a menudo después de que ya se hayan tomado (¿robado?) sin compensación alguna, Wikipedia ha impuesto pocas restricciones sobre cómo las empresas de IA usan sus entradas escritas por voluntarios. Aún así, Deckelmann dijo que espera que siga habiendo incentivos para que la gente siga contribuyendo, especialmente a medida que una avalancha de contenido basura barato y generado automáticamente comienza a contaminar Internet. Las empresas de IA deberían «preocuparse por cómo el contenido generado por humanos sigue existiendo y siendo accesible», añade.
Todas estas empresas de milmillonarios se han lanzado a esta carrera desenfrenada porque ahora mismo no están sujetos a ningún tipo de legislación que se lo impida, sobre todo en aspectos relacionados con la propiedad intelectual. Uno de los críticos de estos y otros aspecto negativos de las IA es Noam Chomsky, quien sostiene que la IA es plagio de alta tecnología y una forma de evitar la educación.
En este sentido, la venta de los datos de Reddit se ha realizado sin el consentimiento de aquellos que escribieron en sus foros. Es una vuelta de tuerca más de la web 2.0. El usuario pone el contenido, pero, además, renuncia a cualquier derecho sobre el mismo.
Desde la perspectiva de los desarrolladores de IA, el estudio de Epoch dice que pagar a millones de humanos para generar el texto que necesitarán los modelos de IA es poco probable que sea una forma económica de impulsar un mejor rendimiento técnico.
Mientras OpenAI comienza a trabajar en el entrenamiento de la próxima generación de sus grandes modelos de lenguaje GPT, el director ejecutivo Sam Altman dijo a la audiencia en un evento de las Naciones Unidas el mes pasado que la compañía ya ha experimentado con «generar muchos datos sintéticos» para el entrenamiento.
«Creo que lo que se necesita son datos de alta calidad. Hay datos sintéticos de baja calidad. Hay datos humanos de baja calidad», dijo Altman. Pero también expresó reservas sobre depender demasiado de datos sintéticos en lugar de otros métodos técnicos para mejorar los modelos de IA.
«Sería algo muy extraño si la mejor manera de entrenar un modelo fuera simplemente generar como un billón de tokens de datos sintéticos y volver a alimentarlos. De alguna manera eso parece ineficiente», dijo Altman.
Copyleft: atribuir con enlace a https://neofronteras.com
Fuentes y referencias:
Preprint en ArXiv.

4 Comentarios
RSS feed for comments on this post.
Lo sentimos, esta noticia está ya cerrada a comentarios.






lunes 24 junio, 2024 @ 6:29 pm
Creo que no debemos confundir ni comparar la IA de ChatGPT o similares con la IA utilizada en contextos especializados. Un principio básico de la informàtica dice que si a un ordenador le das basura, obtendrás basura. Y el artículo está penosamente en lo cierto cuando dice que la alimentación con datos basura o premeditadamente falsos (fakes), o la retroalimentación misma, acabará con una IA totalmente corrupta, inutil o (en el mejor de los casos) que no cumplirá con los requisitos para la que fué concebida.
Però hay contextos específicos en los que esto es más dificil que pase. Por ejemplo en el campo de ciertos diagnósticos médicos. Aquí el sistema se nutre exclusivamente de casos reales diagnosticados correctamente y la IA puede emitir un diagnóstico con un determinado porcentaje de certidumbre. Por supuesto, la responsabilidad final siempre és del médico.
Por otro lado, como suele pasar, la técnica va por delante de las protecciones legales al ciudadano. No pasarà mucho tiempo sin que tengamos la necesidad de llegar a acuerdos internacionales serios sobre el uso y las limitaciones de la IA.
Saludos
lunes 24 junio, 2024 @ 6:31 pm
Se me olvidaba: un excelente artículo.
lunes 24 junio, 2024 @ 6:49 pm
Mas:
«Sam Altman dijo a la audiencia en un evento de las Naciones Unidas el mes pasado que la compañía ya ha experimentado con «generar muchos datos sintéticos» para el entrenamiento.»
He trabajado con algoritmos QSAR (Quantitative Structure Activity Relatioships) en el campo de la investigación de nuevos fármacos. Se trata de predecir propiedades en base a la estructura química de la sustancia. Los datos de entrenamiento para estos algoritmos han de ser necesariamente extraídos de propiedades reales de un pool bastante grande de moléculas con propiedades conocidas (cuanto más grande, más certidumbre en la predicción). No pueden usarse datos generados por el propio algoritmo porque esto harái que el sistema entre en un círculo que alteraría la predictibilidad de los resultados.
miércoles 10 julio, 2024 @ 2:13 pm
Me siento como un pitoniso, en esta misma web hice un comentario sobre las IA: https://neofronteras.com/?p=8155#comment-523138
Las IA tienen el mismo problema energético del bitcoin, quizás hasta peor, el costo del mantenimiento es vulgar y para colmo, CREO que el retorno de beneficios no lo justifica.
ATENCIÓN: las IA si van a hacerse un nicho de mercado donde van a ser muy útiles (como el bitcoin), las IA no van a desaparecer (ni el bitcoin), pero no van a acabar con el mundo (el bitcoin no pudo acabar con los bancos centrales)
Al final, creo que muchas veces las IA van a ser como los lentes de realidad virtual: todas las grandes corporaciones tienen su propia versión, solo para demostrar que son parte del club de las empresas gigantes